一种基于多特征融合深度神经网络的焦炭需求预测方法
本发明属于计算机集成预测,具体的说是一种基于多特征融合深度神经网络的焦炭需求预测方法。
背景技术:
1、焦炭作为高炉炼铁过程中的关键物资,不仅起到还原剂的作用,同时也是能量的主要来源。准确地预测焦炭需求对于确保智能焦化厂的成本效益及其环境可持续性具有决定性的影响。需求预测的准确性直接关系到生产者和消费者能否有效地规划生产、库存和采购策略,以减少不必要的成本,并提高供应链的整体效率和响应速度。在全球日益增长的环保意识和可持续发展要求的背景下,优化焦炭需求预测模型可以有助于减少碳排放,推动环保生产。尽管如此,对焦炭需求预测的研究仍然不充分,面临诸多挑战。这些挑战的原因是多方面的。首先,焦炭市场的专业性和规模相对较小,研究人员和企业的关注度有限。其次,市场对经济周期的依赖性强,需求受到多种经济和非经济因素的影响,增加了预测的复杂度。此外,市场数据的可获取性以及数据质量问题也限制了预测方法的发展。
2、在预测方法上,传统的统计和计量经济学方法,如自回归综合移动平均模型(arima)、最小绝对收缩和选择操作符(lasso)以及广义自回归条件异方差(garch)等,尽管它们在简单性上有一定优势,但往往缺乏对市场动态复杂性的适应能力,特别是在处理非线性模式和捕捉市场情绪方面的局限性。这些方法在数据多维度和非结构化特征面前也显得不够强大。与此同时,人工智能方法,如随机森林、贝叶斯神经网络和极端梯度提升(xgboost)等,虽然在处理大数据集和揭示市场动态方面具有潜力,但仍受限于对数据全面性和有效性的高要求,以及这些模型本身在特征提取方面的局限。深度学习技术的出现为这一领域带来了新的机遇。长短期记忆网络(lstm)、门控递归单元(gru)以及更进阶的模型如双向门控递归单元(bigru)和双向长短期记忆网络(bilstm)等,通过自动学习数据中的复杂模式,提高了预测的准确度。然而,即便如此,深度学习模型在特定情况下可能无法充分利用所有相关数据,其预测结果的精度和可靠性仍有改进的空间。
3、总体而言,焦炭需求预测研究的不足在于对市场动态的理解不够深入,模型的特征提取能力有限,以及对实时数据和非结构化信息处理的不足。目前需求预测方法缺少集中提高模型的动态适应能力,融合更多类型的数据源,以及开发更为高级的算法来综合这些信息。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于多特征融合深度神经网络的焦炭需求预测方法,以期能够提升数据的综合分析能力,优化特征提取的效能,并从多维度视角深入挖掘特征信息,实现对焦炭需求的高精度预测。
2、本发明为达到上述发明目的,采用如下技术方案:
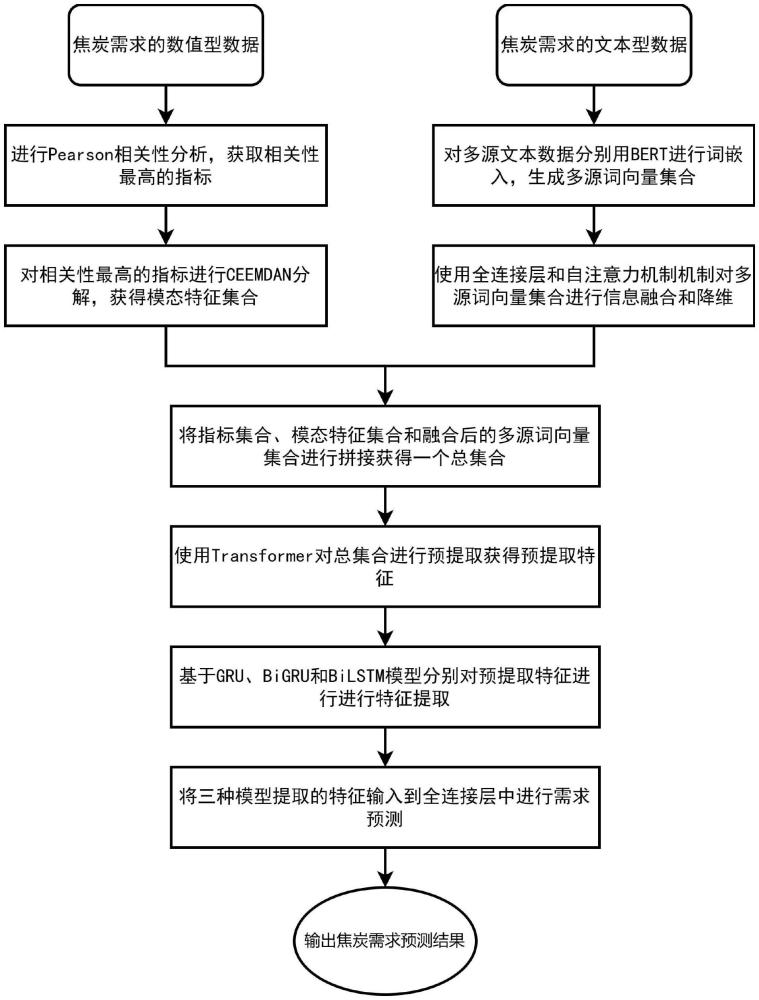
3、本发明一种基于多特征融合深度神经网络的焦炭需求预测方法的特点在于,是按如下步骤进行:
4、步骤1、对焦炭需求的数值型指标集合p进行预处理,得到模态特征集合imf;
5、步骤2、对焦炭需求的文本型数据集进行预处理,得到总词向量集合x”;
6、步骤3、将数值型指标集合p、模态特征集合imf和分配权重后的总词向量集合x”进行拼接后,得焦炭需求输入数据集r={p,imf,x”};
7、步骤4、构建由transformer网络、特征提取模型和全连接层构成的多特征融合深度神经网络;
8、步骤4.1、所述transformer网络对r进行特征融合的预提取处理,得到数值-模态-文本融合特征r';
9、步骤4.2、构建由gru模型、bigru模型、bilstm模型组成的特征提取模型并进行特征提取:
10、步骤4.2.1、基于gru模型对r'进行特征提取,得到焦炭需求动态特征其中,表示第s个焦炭需求动态特征,s∈[1,s];s表示焦炭需求动态特征的总数;
11、步骤4.2.2、基于bigru模型对r'进行特征提取,得到焦炭需求全景特征其中,表示第s个焦炭需求全景特征;
12、步骤4.2.3、基于bilstm模型对r'进行特征提取,得到焦炭需求深度序列特征其中,表示第s个焦炭需求深度序列特征;
13、步骤4.3、将ygru、ybigru和ybilstm拼接后输入到全连接层中进行需求预测,得到预测的焦炭需求y;
14、步骤5、基于预测结果y计算均方误差并作为目标函数j,从而利用反向传播和梯度下降法对所述多特征融合深度神经网络进行训练,使得目标函数j达到最小,当迭代次数达到最大迭代次数时,停止训练,从而得到训练后的焦炭需求预测模型,用于焦炭需求的预测。
15、本发明所述的一种基于多特征融合深度神经网络的焦炭需求预测方法的特点也在于,所述步骤1是按如下步骤进行:
16、步骤1.1、构建焦炭需求的数值型指标集合p={p1,p2,…,pn,…,pn},其中,pn表示第n个指标,n∈[1,n],n表示指标总数,且pn={pn,1,pn,2,…,pn,m,…,pn,m},其中,pn,m表示第n个指标pn中第m个时间的特征参数,m∈[1,m],m表示时间总数;
17、步骤1.2、令当前经验模态分解个数为k,并初始化k=1;
18、步骤1.3、对焦炭需求的指标集合p中的每个指标分别与其他指标进行pearson相关性分析,从而找到相关性最高的一个指标pu,从而在pu中第i次加入第k-1个幅值为εk-1的高斯白噪声vi后,得到第i个特征信号i∈[1,i];i表示加入总次数;
19、步骤1.4、对进行经验模态分解,得到经过经验模态分解后的第k个本征模态分量从而利用式(2)得到第k个本征模态分量imfk,并利用式(3)得到第k个残差rk;
20、
21、rk=pu-imfk (3)
22、步骤1.5、在第k个残差rk中第i次加入添加第k个幅值为εk的高斯白噪声vi,得到第i个新的特征信号r1+ε1vi,从而利用式(4)得到第k+1个本征模态分量imfk+1;
23、
24、式(4)中,e表示经验模态分解操作;
25、步骤1.6、利用式(5)计算第k+1个残差rk+1;
26、rk+1=rk-imfk+1 (5)
27、步骤1.7、将k+1复制给k后,返回步骤1.5顺序执行,直到剩余的残差为单调函数为止,从而得到模态特征集合imf={imf1,imf2,…,imfk,…,imfk},k表示模态特征的总数,且imfk={imfk,1,imfk,2,…,imfk,m,…,imfk,m},imfk,m表示imfk中第m个时间对应模态参数。
28、所述步骤2是按如下步骤进行:
29、步骤2.1、收集焦炭需求的多源文本集合,包括:投资者评论文本集合t1={t1,1,t1,2,…,t1,m,…,t1,m}、研究报告文本集合t2={t2,1,t2,2,…,t2,m,…,t2,m}和新闻文本集合t3={t3,1,t3,2,…,t3,m,…,t3,m},其中,t1,m表示第m个时间的投资者评论文本数据,且表示t1,m中第a个投资者评论单词,a∈[1,a],a表示t1,m的投资者评论单词总数;t2,m表示第m个时间的研究报告文本数据,且表示t2,m中第b个研究报告单词,b∈[1,b],b表示t2,m的研究报告单词总数;t3,m表示第m个日期的新闻文本数据,且其中,表示t3,m中第c个新闻单词,c∈[1,c],c表示t3,m的新闻单词总数;
30、步骤2.2、对t1,m、t2,m和t3,m经过预处理后,分别截取d个单词,再使用预训练模型bert分别对截取的d个单词进行词嵌入,相应得到第m个时间的投资者评论词向量第m个时间的研究报告词向量集合以及第m个时间的新闻词向量集合从而得到投资者评论词向量集合x1={x1,1,x1,2,…,x1,m,…,x1,m}、研究报告词向量集合x2={x2,1,x2,2,…,x2,m,…,x2,m}和新闻词向量集合x3={x3,1,x3,2,…,x3,m,…,x3,m};其中,表示第d个投资者评论词向量,表示第d个研究报告词向量,表示第d个新闻词向量,其中,d∈[1,d],d表示词向量的长度;
31、步骤2.3、将投资者评论词向量x1、研究报告词向量x2和新闻词向量x3转置后进行拼接,得到总词向量集合其中,t表示转置;
32、步骤2.4、用全连接层对总词向量集合x进行降维和信息交换,获得降维维度后的词向量集合x'={x1,x2,…,xe,…,xe},其中,xe表示总词向量集合x中第e个维度的词向量特征,e∈[1,e];e表示词向量特征的总维度;
33、步骤2.5、利用式(7)和式(8)计算特征分配的权重值α,从而利用式(9)得到分配权重后的总词向量集合x”;
34、g=tanh(x′) (7)
35、α=softmax(wg) (8)
36、
37、式(7)-式(8)中,tanh是指双曲正切函数,softmax是激活函数,w是参数。
38、所述步骤4.1是按如下步骤进行:
39、步骤4.1.1、利用式(10)-式(12)得到数值-模态-文本信息交互特征multihead;
40、
41、
42、multihead=concat(head1,head2,…,headl,…,headl)w0 (12)
43、式(10)-式(12)中,ql表示第l个注意力头的查询矩阵、kl表示第l个注意力头的键值矩阵,vl表示第l个注意力头的值矩阵;分别对应ql、kl、vl的系数矩阵,l表示注意力头的总数,l∈[1,l];headl表示第l个注意力头,dk表示kl的维度;w0表示线性变换的权重矩阵;concat表示拼接;
44、步骤4.1.2、所述transformer网络利用式(13)-得到式(15)得到数值-模态-文本融合特征r':
45、multihead′=norm(r+multihead) (13)
46、ffn(multihead')=relu(multihead'w1+f1)w2+f2 (14)
47、r′=norm(multihead′+ffn(multihead)) (15)
48、式(13)中,norm表示归一化操作;+表示残差连接;式(14)中,ffn表示前馈神经网络,relu表示激活函数,w1和w2表示前馈神经网络中的两个权重矩阵,f1和f2表示前馈神经网络中的两个偏置项;relu表示激活函数。
49、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述焦炭需求预测方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
50、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述焦炭需求预测方法的步骤。
51、与现有技术相比,本发明的有益效果在于:
52、1.增强数据综合能力:本发明构建的多源多模态数据集能更全面地反映焦炭需求的影响因素,集合了不同类型的数据,如数值型的需求指标、文本型的投资者评论、研究报告和新闻等,从而提供了更为丰富的信息支持。
53、2.改善特征提取性能:本发明通过将需求指标数据和文本数据分别预提取,能更准确地提取到每种模态下最为关键的特征,首先选择完全自适应噪声集合经验模态分解(ceemdan)方法作为信号分解技术对相关性最高的指数特征进行分解,该方法凭借其出色的去噪和信号分解能力,可以提供清晰准确的模态特征。在文本数据预提取方面,本发明将对多源文本数据先分别用bert进行词嵌入,经过全连接层的降维和信息融合后用自注意机制进一步提高了文本特征提取的准确性和全面性。
54、3.模型创新:本发明应用基于transformer和多种循环神经网络(如gru、bigru、bilstm)的融合模型,可以更有效地处理时间序列数据,并充分捕捉需求特征间的非线性关联和长期依赖性。注意力机制的使用进一步优化了特征的权重分配,使模型更加集中于影响预测结果的关键信息。
55、4.特征融合与预测效果:本发明多特征融合策略有助于整合各个模态的特征,利用各自特征的优势来提升预测模型的泛化能力。这种融合预测可能比单一模态的预测结果更为准确和可靠。
56、5.应对动态市场变化:本发明所提出的方法考虑到市场的动态性,通过实时数据处理能力和对非结构化信息的高效利用,以及多模态数据的综合分析,使预测模型能够更快地适应市场变化。
技术研发人员:朱旭辉,马成功,夏平凡,彭张林,倪志伟,倪丽萍
技术所有人:合肥工业大学
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除