基于同类目标融合数据增广的鲁棒X光图像目标检测方法
本发明涉及计算机视觉,尤其涉及基于同类目标融合数据增广的鲁棒x光图像目标检测方法。
背景技术:
1、目标检测是计算机视觉中的一个重要问题,指的是在一张图像中识别出哪些区域是目标对象,并且给出这些目标对象的位置和大小及类别。目标检测在计算机视觉应用中非常广泛,如自动驾驶汽车、无人机、安防监控等。在安防监控的应用场景中,有一类场景的图像是以x光成像的,如机场、车站、地铁站的安检仪器输出的图像,这就需要x光图像的目标检测,用于解决安检过程中危险品的自动检测任务。
2、近年来随着深度学习的发展,越来越多的计算机视觉方面的应用开始使用基于深度学习的方法,x光安检图像检测同样也进入了深度学习的时代。早期的x光图像目标检测使用的是基于手工特征的方法,这些方法的效果并不理想。由于基于统计的深度学习需要有大量数据用作训练,但是当时并没专门用于x光安检大型数据集,这就使得卷积神经网络在最开始不能很好地应用于该领域,但随后迁移学习方法的出现,使得这一情况发生了改变。2016年,akcay等人(s,kundegorski m e,devereux m,et al.transferlearning using convolutional neural networks for object classification withinx-ray baggage security imagery[c]//2016ieee international conference on imageprocessing(icip).ieee,2016:1057-1061.)为了克服缺少数据的问题,首次在x光安检图像检测领域使用迁移学习,在alexnet的基础上对卷积层和全连接层参数进行微调,该方法相较之前的方法取得了更好的成绩,这是深层卷积神经网络在x光安检图像检测方面的首次研究。在这之后,越来越多的基于深度学习的方法在该领域得到应用。miao等人(miao c,xie l,wan f,et al.sixray:a large-scale security inspection x-ray benchmarkfor prohibited item discovery in overlapping images[c]//proceedings of theieee/cvf conference on computer vision and pattern recognition.2019:2119-2128.)提出了一个大规模的x光安检数据集sixray,同时他们还使用了一种类别平衡的层次化精炼方法,实验表明该方法可以很好地解决正负样本不均衡的问题,同时他们还设计了一个类平衡损失函数以缓解易负样本引入的噪声。wei(wei y,tao r,wu z,etal.occluded prohibited items detection:an x-ray security inspection benchmarkand de-occlusion attention module[c].acm multimedia 2020.)等人提出了针对安检场景下的目标检测任务而设计的高质量数据集opixray,该数据集中所有图片所包含的危险品都由某机场的专业安检员手动标注。此外,该论文还提出了一种用于检测安检场景下遮挡的违禁物品的方法,该方法的核心利用了注意力机制来增强x光图片中违禁品的边缘信息和材料信息。但是以上这些方法大多都依赖于一个大规模的数据集来进行模型训练,但是由于x光图片中存在着严重的物体重叠遮挡的情况,这导致数据集的标注相比其它任务更为困难。因此获取一个标签完全准确的大规模x光图片数据集是非常困难的,事实上,目前的大部分x光数据集中都或多或少的存在着噪声问题,包括目标边界框不准确和目标类别错误。而模型在含有噪声的数据集上进行训练时,训练的精度可能会严重受这些噪声数据影响,因此,设计一个噪声鲁棒的x光违禁品检测方法是非常有必要的。
技术实现思路
1、有鉴于此,本发明的目的在于提出一种实施可靠、泛用性佳、抗噪声能力好的基于同类目标融合数据增广的鲁棒x光图像目标检测方法。
2、为了实现上述的技术目的,本发明所采用的技术方案为:
3、一种基于同类目标融合数据增广的鲁棒x光图像目标检测方法,其包括如下步骤:
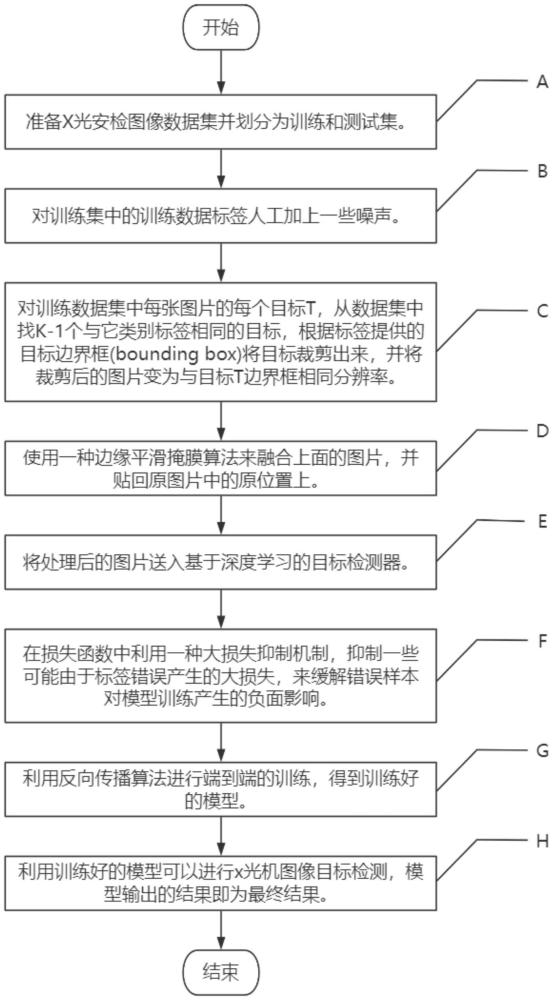
4、a、准备x光安检图像的数据集,将其划分为训练集和测试集,其中,训练集和测试集的图片数据均具有指向目标对象的类别标签和目标边界框标签;
5、b、在训练集的图片数据中加入标签噪声,以模拟噪声情况,所述噪声可以通过人工方式添加,其包括类别标签噪声和目标边界框标签噪声;
6、c、针对训练集中每份图片数据的每个目标对象t,从数据集的图片数据中找出k-1个与其类别标签相同的图片数据,然后根据图片数据对应的目标边界框(bounding box)标签,将目标对象剪裁出,再将剪裁出的图片分辨率转换为与目标对象t边框相同的分辨率;
7、d、使用边缘平滑掩膜算法将剪裁出的目标对象的图片重新贴回原图片数据的原位置上;
8、e、将经步骤d处理后的训练集的图片数据送入基于深度学习的目标检测器中,以用于模型训练;
9、f、在目标检测器对应模型的损失函数中利用预设大损失抑制机制,以抑制因图像数据的标签错误产生的大损失,来缓解标签噪声对模型训练产生的负面影响;
10、g、利用反向传播算法进行端到端的模型训练,且在模型通过测试集的测试后,得到训练好的模型;
11、h.利用训练好的模型进行x光机图像目标检测,通过模型输出的检测结果。
12、作为一种可能的实施方式,进一步,本方案步骤a中,所准备的x光安检图像的数据集包括opixray、pidray和ms-coco。
13、本方案所用的数据集opixray是一个包含了folding knife、straight knife、scissor、utility knife和multi-tool knife的x光图像数据集,由8885张x光图像组成,其中7109张图片被划分为训练集,剩余1776张图片被划分为测试集。
14、数据集pidray是一个包含47677张图片的较大型x光数据集,数据集中包含12个不同的类别,其中29457张图片用于训练,18220张图片用于测试。
15、数据集ms-coco是一个公开的大型通用目标检测数据集,其中包含了135000张训练图片和5000张测试图片,数据集中包含了80个不同的类别。本方案使用opixray和pidray两个x光数据集来测试本方案方法在噪声标签情况下x光违禁品检测任务上的性能,用ms-coco来验证本发明方案在其它任务上也有很好的泛化性能。
16、由于很难正确的得出某个数据集的噪声水平,同时也较难找到具有特定噪声率的数据集。为了测试不同噪声率下本方案的性能,作为一种较优的选择实施方式,优选的,本方案步骤b中,在训练集的图片数据中加入标签噪声,以模拟噪声情况包括:对目标对象的类别标签和目标边界框标签分别加上标签噪声;
17、其中,对类别标签加上标签噪声的方法为:以预设概率将图片数据原始的类别标签替换为数据集中任意其它类别的标签,该预设概率即为数据集的类别噪声率;
18、对目标边界框标签加上标签噪声的方法为:以预设概率对图片数据原始的边界框进行偏移和放缩,该预设概率即为数据集的目标边界框噪声率;将坐标(x,y,w,h)设为图片数据的边界框,预设概率执行以下操作:
19、
20、其中,δx,δy,δw,δh是从一个均匀分布u(-δ,δ)中随机采样得到的,δ表示噪声的扰动等级,x,y,w,h为图像数据中指向目标对象的边界框坐标,为加入噪声后的边界框坐标;作为一种举例,可以设置δ=0.3。
21、作为一种较优的选择实施方式,优选的,本方案步骤c包括:对于训练集中每份图片数据中的每个目标对象t,该目标对象t对应的标签中含有指向目标对象位置信息的目标边界框标签和目标对象类别信息的类别标签;根据标签提供的类别信息,从原始的数据集中找k-1个具有相同类别信息的目标对象的图片,并根据其对应的目标边界框标签将图片数据中的目标对象裁剪出来,放入结果集中;
22、其中,每次从数据集中随机挑选一张图片数据,如果该图片数据中包含与目标对象t对应标签中类别信息相同的目标对象,则根据其对应的目标边界框标签将其中的目标裁剪出来,再将裁剪后的目标对象的图片分辨率变为与目标对象t相同的分辨率后添加到结果集合中,否则重新从数据集中随机选择一张图片数据,直至结果集合中包含k-1个相同分辨率的目标。
23、作为一种较优的选择实施方式,优选的,本方案步骤d包括:
24、对于结果集中的所有目标对象以及其对应原始的目标对象t,将其融合到同一张图片中来增大对应类别标签的目标对象在目标边界框中出现的概率,以减小因为噪声原因导致目标边界框中不存在对应类别标签的目标对象的概率;为了使融合更加平滑,得到的最终结果看起来更加自然,通过边缘平滑掩膜算法对图片数据进行融合,其对应的计算公式为:
25、
26、其中,di,j是目标边界框中位置(i,j)的像素和边界框最近边的距离,其值为min(i,j,ho-i,wo-j),ho,wo分别为裁剪后目标的高和宽,β是为一个控制平滑边界范围的阈值,λ是从beta分布中随机采样的一个数字;
27、使用边缘平滑掩膜对结果集合中的图片进行融合,融合的公式为:
28、
29、其中,α为边缘平滑掩膜,ba为原始目标对象t对应的图片块,bn为结果集中的图片块,k为融合图片的总数,为逐元素乘;
30、最后将融合好的图片贴回原图片数据中目标对象t所在的位置,完成融合过程。
31、通过上述图片融合过程,可以显著的降低类别噪声和边界框噪声的噪声率。假设一个噪声率为p的数据集中有一个标签的类别为c,则这个边界框标签中真正含有类别c的目标的概率为1-p,当此时融合k个具有相同类别的目标图片块,则融合后的边界框中含有目标的概率就变为了1-pk,因为p是0-1之间的数字,因此边界框中含有目标的概率将会大大提升。
32、作为一种较优的选择实施方式,优选的,本方案步骤e中,所述基于深度学习的目标检测器以faster rcnn作为基础目标检测网络,其核心部分包括基础特征提取网络、区域提议网络和区域分类与边界回归网络三个部分,分别用于特征提取,从特征图中选出候选区域和对每个候选区域进行分类和边界框回归。faster rcnn通过端到端的训练实现了高效的目标检测,相较于传统的两阶段方法,它在速度和准确性上都取得了显著的提升。虽然本发明主要使用faster rcnn进行实验,但由于本方法主要在图片层面做修改,因此也可根据任务需求应用于其它目标检测网络中。
33、本方法在经过步骤e融合多个目标后,由于噪声影响,一个位置可能会出现多个不同类别的目标,但是其共用一个标签。即使模型对于图片中出现的这些目标都进行预测,那些由于噪声而出现的其它类目标因为没有正确的标签,即使预测正确了也会被视为错误预测而被抑制,导致模型性能下降。为了缓解这种“假错误”预测对模型训练产生的影响,作为一种较优的选择实施方式,优选的,本方案步骤f包括:
34、将目标检测器对应模型所有的预测分为4类,分别为:
35、(1)pbneg:模型预测目标边界框与标签边界框的iou小于阈值;
36、(2)pbpp:模型预测目标边界框与标签边界框的iou大于阈值,但是预测类别与标签类别不同且不为背景;
37、(3)pbfb:模型预测目标边界框与标签边界框的iou大于阈值,且预测类别为背景;
38、(4)pbpos:模型预测目标边界框与标签边界框的iou大于阈值,且预测类别与标签相同;
39、其中,“假错误”预测主要就是pbpp所包含的预测结果,将这部分预测结果从损失函数计算中舍去,只计算其它三个部分的分类损失,最后总的损失函数变为:
40、l=lbbox+lclsneg+lclspos+lclsfb
41、其中,lbbox表示回归损失,不对它进行变化,lclsneg,lclspos,lclsfb分别表示上述pbneg,pbpos,pbfb对应的分类损失。
42、作为一种较优的选择实施方式,优选的,本方案步骤g还包括对数据进行预处理,其包括:使用随机翻转数据增强,对所有训练集和测试集的数据进行数据归一化;所述基础特征提取网络用在imagenet预训练的resnet来初始化开始训练,以随机梯度下降作为优化器,其中,初始学习率为0.0025,在训练的第17轮和21轮时,分别将学习率缩小10倍,权重衰减参数为0.0001,动量参数为0.9;每次迭代的mini-batch设置为2,整个网络训练24轮;在训练过程中,使用所述预设大损失抑制机制来修改损失函数,计算完损失之后,使用梯度下降算法进行反向传播,更新模型参数。
43、作为一种较优的选择实施方式,优选的,本方案步骤h包括:将待检测的输入图像的分辨率变换为1333*800,然后输入到经训练好的用于x光安检图像目标检测的模型中,通过模型将提取的特征输入回归网络得到检测边界框坐标值,再输入到分类网络中预测其对应的类别,生成检测结果。
44、采用上述的技术方案,本发明与现有技术相比,其具有的有益效果为:本方案方法可以有效地消除标签噪声对x光安检图像目标检测器训练产生的影响,并且通过图像融合很好的模拟了x光图像中重叠遮挡的情况,让模型可以更好的学习到x光图片的固有特征。该方案不仅在多个公开地数据集上都取得了良好的性能,同时相比于传统的噪声标签学习方法,是一种更加灵活,且贴近实际需求地解决噪声标签情况下x光安检图像目标检测的方案。除此之外,通过实验结果发现,本方案方法不仅在x光数据集中有效,在一些通用目标检测数据集中也有较好的效果。
技术研发人员:严严,陈睿康,王菡子
技术所有人:厦门大学
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除